Abstract
Lane detection is an essential function for autonomous vehicles. While GPS and HD maps offer accurate localization under optimal conditions, vision-based detection provides an important backup, especially in areas with weak GNSS signals or outdated maps.
This system implements a deep-learning lane detection pipeline using a convolutional autoencoder, designed to identify and segment multiple lane boundaries in various road conditions using only front-facing camera images.
The approach integrates image preprocessing, deep-learning inference, optional temporal tracking, and curve fitting to generate stable and clean lane boundaries. It has been tested in real-world driving and in simulators such as Carla and Scaner.
Example detections:



Deep Learning Architecture
Global Pipeline
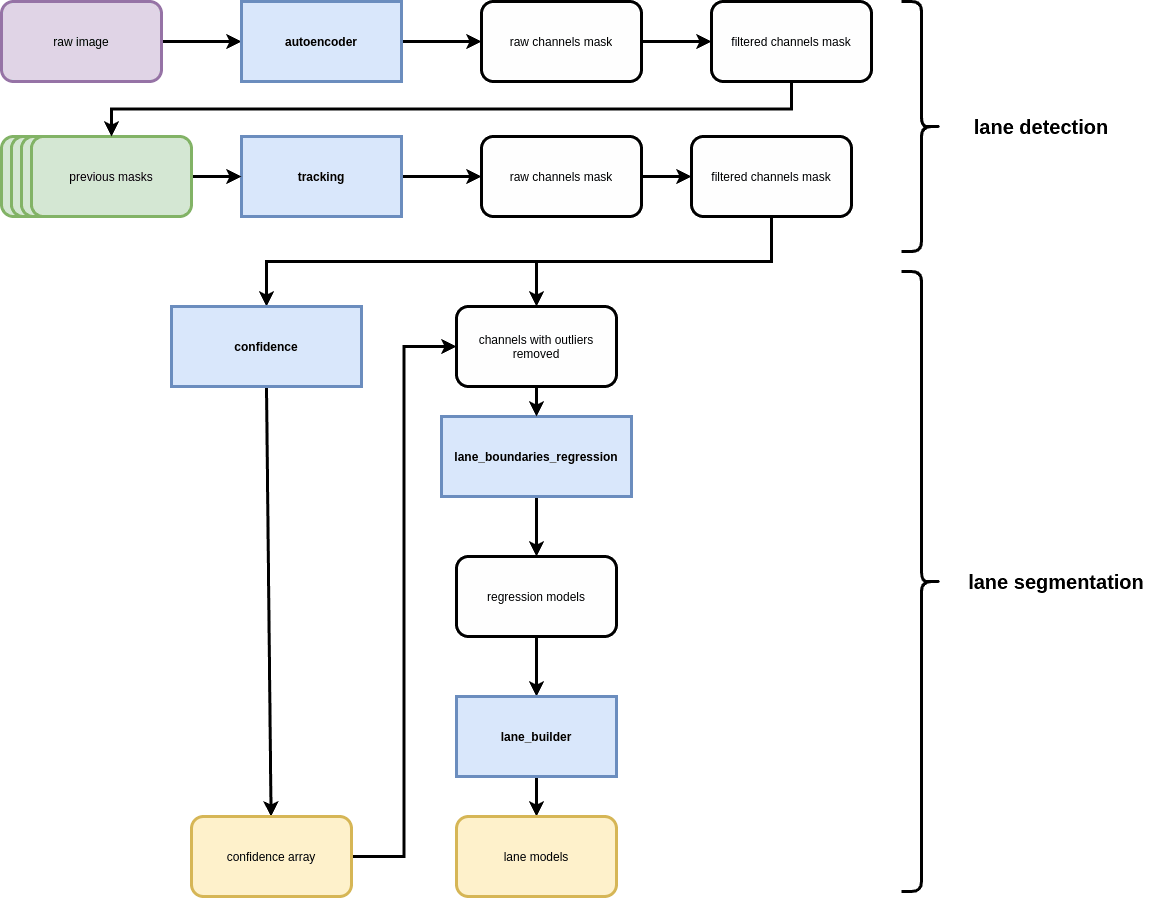
The system is organized into several modules:
- Autoencoder: Produces binary lane masks from camera input.
- Tracker (optional): A ConvLSTM-based temporal model for improved frame-to-frame stability.
- Lane Regression: Fits polynomial curves to lane masks.
- Post-processing: Removes outliers and can generate drivable region segmentation.
Autoencoder Design
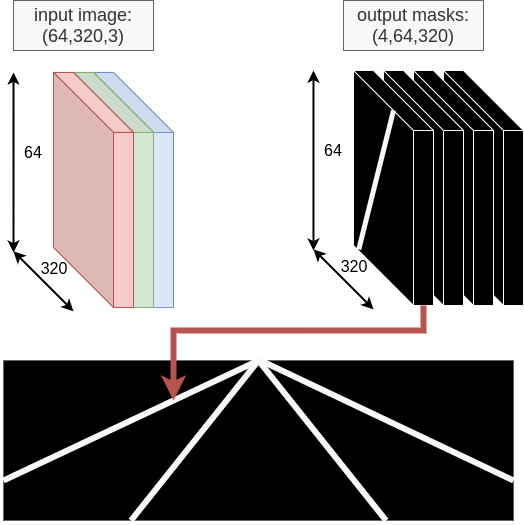
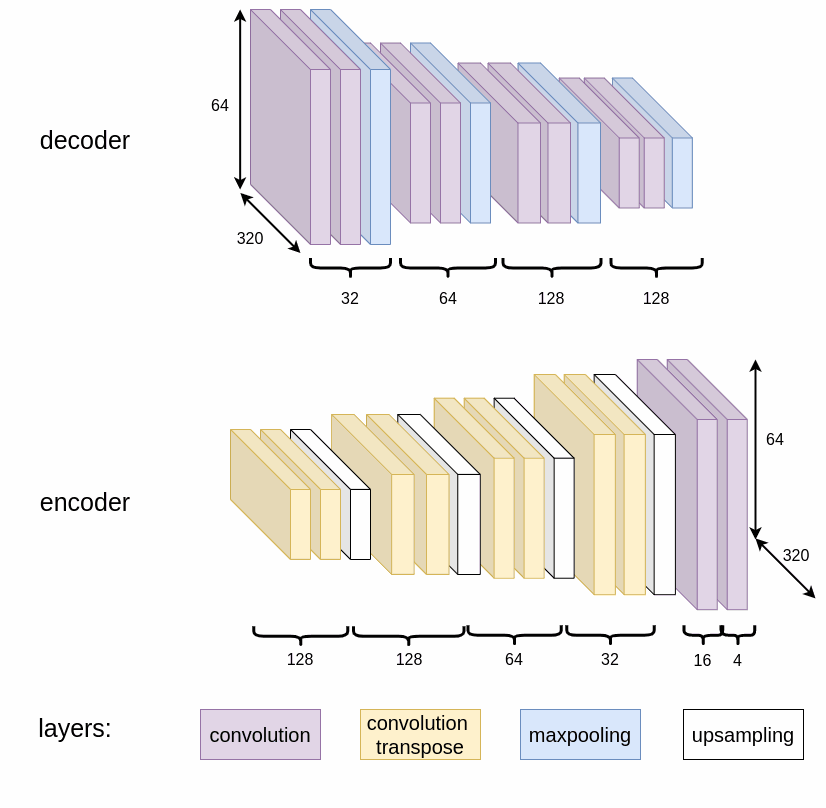
The convolutional autoencoder performs lane segmentation by encoding spatial information and decoding it into four binary masks: left border, left middle, right middle, and right border.
Each block contains convolution layers, batch normalization, and ReLU activation. The decoder upsamples using transpose convolutions to restore the original resolution.
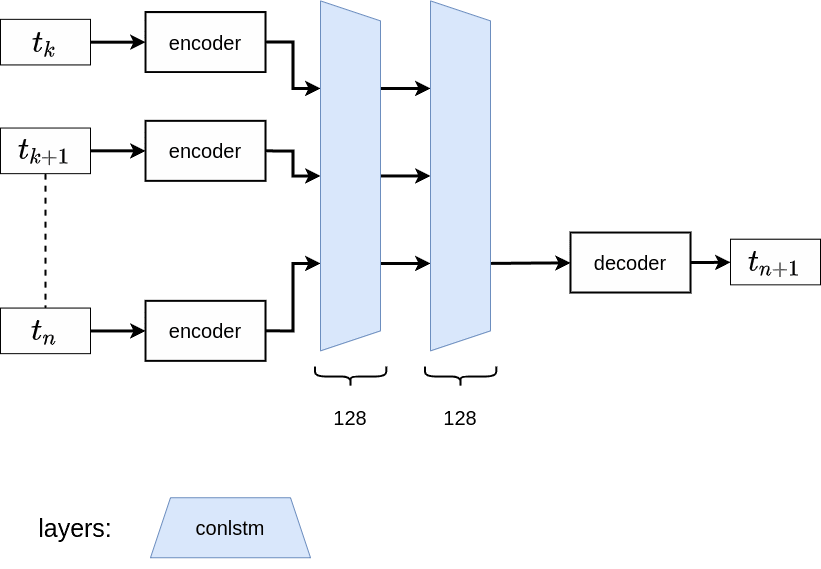
Tracking Module (Optional)
The ConvLSTM tracker improves predictions by considering the previous N frames, reducing noise and bridging gaps. Training includes noise-augmented data for robustness.
![]()
![]()
![]()
![]()
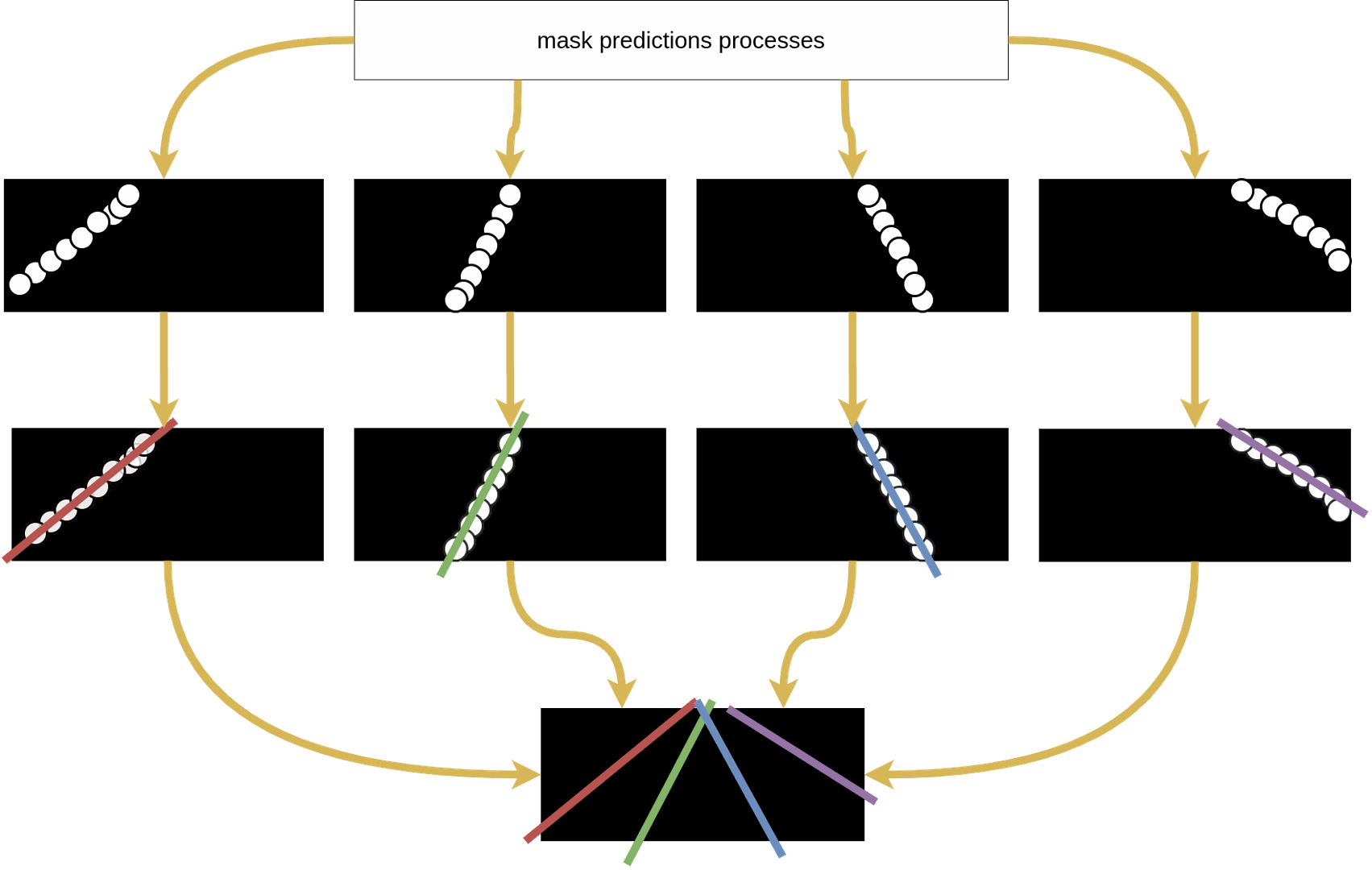
Post-processing and Lane Regression
After mask prediction, RANSAC polynomial regression fits curves to each lane boundary, rejecting outliers for consistent results.

Visual Results
The model performs well with occlusions, worn markings, curves, and lighting variations.




Real-world example:
Simulator examples:
Carla
Scaner
Integration with Visual Servoing
After lane detection, a local path reference is computed.
A visual servoing controller adjusts linear velocity $v$ and angular velocity $w$ to minimize deviation from the detected lane centerline.
Dataset
The model is trained on the CuLane dataset, converted into binary masks using a custom preprocessing script.